移动端效率:VertexTextureFetch
发布于:
## 引入 叠甲:本人菜菜,说错了别怪我qwq 由于非常神奇的项目要求,现在**每一块**海洋的顶点是在cpu内生成出来的,切到别的lod就会删除现在的mesh,然后再去算新的网格。 怎么能有这么蠢的代码呢!很生气,于是打算爆改,通过vs里采样texture来获取顶点高度。 > 为什么海洋需要获取高度呢....很神奇...但是我不好解释 然后我把这事报给了组长,组长直接给否了,也没说原因。 后来问了问我们这维护rhi的同学,直接叹气摇头了:“移动端上vs采texture的支持一言难尽啊” 我:”不要忽悠我啊,gles3.0支持的特性,到现在也有10年了,不可能有支持问题的!“ 他们说:”标准是标准,支持不支持又是令一码事情了” 我说:“难道手机上没有高度图大世界渲染咩?” 又说:“这东西效率不太好“ 窝不信窝不信 现在gpu都是统一架构了,再也没有转门的vs处理器和ps处理器,那么贴图采样应该也走的是相同的单元,怎么会有性能区别呢? 那么就用数据(还有vendor的标准)打他们的脸吧! ## 为什么移动端奇奇怪怪的 移动端的内存和显存通常是一体的。为了省电他们用了一种叫lpddr的内存。 lp嘛,一听就很省电(low power) 最新的lpddr5带宽也就....50GB/s 听起来很高?如果我说GDDR6带宽能有2000GB/s呢? 所以在手机上每次的显存写入都得斟酌,也就导致厂家发明了奇奇怪怪的东西。 > 注意,显存带宽应该指的是alu/l1l2 到显存的数据交换能力,对于手机的统一架构,其实说白了就是回写到内存中 ## What does vendor say 首先不讨论IOS平台,他们电脑和手机用的是相同的gpu吧... m1pro可是能转义dx12玩2077的究极怪物,恐怖如斯,vs采样区区雕虫小技怎敢螳臂挡车? > 其实还是要看的,和同事交流下来ios developer的文档最清晰,或许我们能从中一探tbdr的究竟 > 而且mac和手机端的内存芯片应该不一样... Android上厂商太多啦...但总体来说 就 两 家! 一家是前radeon移动团队,认高通为义父的Adreno GPU! 另一家是ARM亲自下场设计,做出来的Mali GPU! 那么现在性能最好的还是高通,所以我们暂时只看高通吧~ 在一切之前,我们都知道移动端都是采用一种叫Tiled Based Rendering的技术,不同于Immediate Mode Rendering,他会先处理所有的primitives,把Primitives分配到不同的tile中(这一步被称为分箱binning pass),然后再对每个Tile进行渲染。 这样做的好处是节省带宽,因为在每个tile之内的渲染,渲染的中间结果完全可以保存在片上缓存中,而不用频繁回写。 试想一个经典的deffered PBR管线,你需要一个Pass绘制出 至少四张gbuffer,然后再用一个全屏pass去组装这些信息,渲染出最终结果。对于传统的IMR模式,在每个片段渲染完成之后就会回写数据到显存中。而在TBR中完全可以把这些同属于一个Tile的中间结果储存在片上内存中,而当最后一个合成pass渲染完成后,才会回写。 这也是为什么vk的renderpass很适合移动端的原因,因为可以用subpass这个概念去构建那些渲染中间结果的pass,比如subpassA是用来填充gBuffer的,而subpassB则是用来合成的,subpassA的output可以作为subpassB的输入,用attachment input就好。更进一步,在这种模型下可以甚至可以不存gbuffer信息,用transient image来提示驱动我们要用片上缓存储存这些中间结果,那么驱动就不会给你分配gbuffer的内存了,只需要最后一个储存颜色输出的buffer,简直神奇爆了! 咳咳扯远了 那么更著名的TBDR呢? 其实就是延迟渲染的硬件解决方案。分箱的同时也会记录可见性信息。 在这里世界线分叉了 高通用的叫LRZ(Low Resolution Z),画了一张低分辨率的深度图来加速分箱,同时也作为一个简易大颗粒的zTest,发生在earlyZ之前进行剔除。 mali的方法叫FPK(Forward Pixel Kill),听着很玄乎,用FIFO链表,可以Kill前面的渲染执行,也能避免后面的overdraw 改变深度比较方向很可能导致这两种策略失效,开启混合会导致失效。 ## TBR杀手 对于adreno,在**VS里过多采样纹理**,使用tessellation,可能导致GPU进入IMR模式 这个结论是 [高通官方文档](https://docs.qualcomm.com/bundle/publicresource/topics/80-78185-2/overview.html?product=1601111740035277#flexrender-technology-hybrid-deferred-and-direct-rendering-mode) 中说的。 所以问题再次回到了VS采样这个问题上。为什么会有这个奇怪的结果呢? 事情回到TBR的执行流程上,相比传统的渲染管线多了一道binning pass,binning pass其实也是有开销的。 这个开销,就是Vertex Shader中计算出输出的Position的代码路径的开销。事实上对于adreno他会编译一份只有position输出的vertex,那么在binning pass,毫无疑问,他会执行这个shader。 那么可想而知,对于一个只有ALU计算的binning pass,他会无比高效,而如果有了texture采样,这个过程就会变得复杂且低效,对于gpu是不可接受的。 而且,窝之前可能说过(也可能没有我不想改之前的东西了),binning pass是对一个pass内所有的draw执行一遍后,才会进入Fragment阶段的。那么在fragment执行的时候,gpu就可以开始执行下一个pass的binning pass了,毫无疑问这样可以充分利用硬件上的气泡:比如说ps采样很多啊,那么下一个pass的binning pass这时候就可以猛猛造ALU,利用空闲的资源。在这种假设下,一个快速的vs可以让整个管线变得更加高效呢。 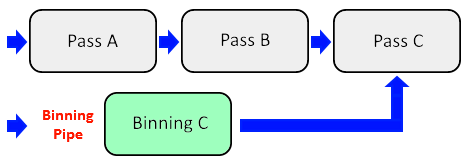 这点果子也有提到哦 [Tailor Your Apps for Apple GPUs and Tile-Based Deferred Rendering](https://developer.apple.com/documentation/metal/tailor-your-apps-for-apple-gpus-and-tile-based-deferred-rendering) > While the GPU runs the final stages of a render pass to tile memory, it can start the vertex stage of a future render pass. The GPU can use more hardware blocks at the same time by running both stages in parallel because they tend to use different compute and memory components. 所以,vertex shader中尽量不要采样texture,这样gpu能更高效的利用不同硬件,达到硬件层面并行渲染。 难道事情到这就结束了么? ## 事实上,实践出真知 事实上我们已经有个render feature在重度使用这项技术了,那就是我一位非常厉害的同事做出来的虚拟纹理地形。 我怂恿他读了这些文章并且让他告诉了窝结论,嘿嘿 当然最重要的是实测 我们做了两个版本的地形,一个版本是直接把数据当成了vertex buffer绑定在draw上,dc比较多;另一个版本是共享了vertex在vs里用虚拟纹理还原了真正的坐标,但是做到了合批一个dc。不管哪个,都有60w个顶点。 在比较新的手机上后者的效率比前者高多了,我们猜想大概率是因为cpu的开销降低了很多。 但这不是旅程的终点,我们成功的让这个地形demo运行在了小米5上,做到了绝对的60帧稳定,并进行了对比。 > 不是我们,是他qwq 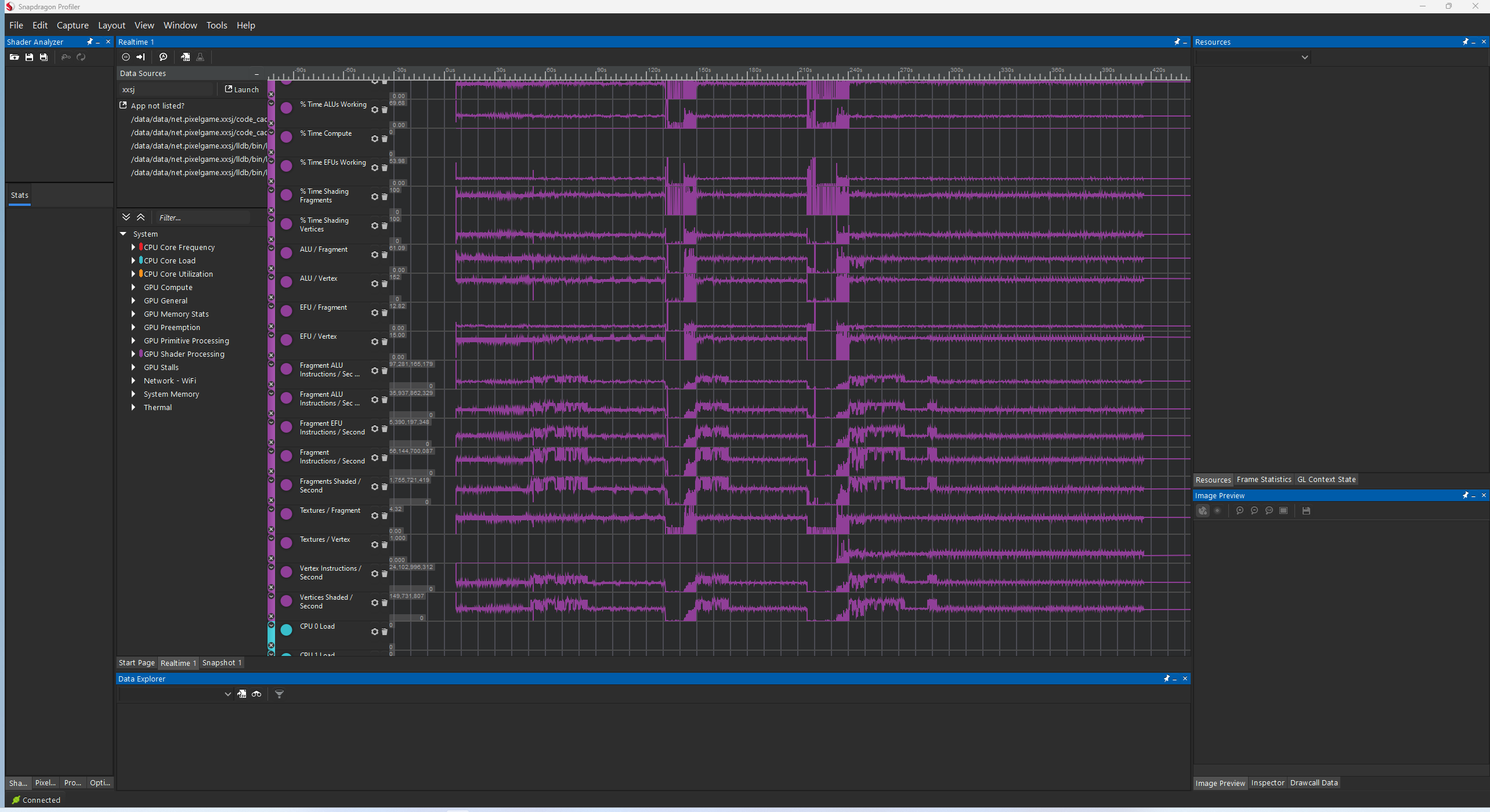 这张图就是最后的结果,放大看,在Texture/Vertex这有一道分界线,就是地形切换成虚拟纹理的时机。 其实可以发现,VS的计算压力并没有明显提升,甚至说保持了一致。而大头永远在ps上,所以vs采样texture只要优化得当,不会是瓶颈。 说到优化,我似乎还有些前提没说,这里每个顶点会采样一次texture,点采样,并且一个顶点精准对应一个texel。 所以能充分利用GPU的采样局部性(不难想象对于这些texture gpu会一次把周围一小块都移动到cache中)。 对于比较跳跃的采样,我觉得不会有什么好结果。 ## 结论 知乎也不是那么靠谱,当初我看了他们讲的tbdr迷迷糊糊,最后还是在厂商(特别是果子,还有高通)的best practice中找到了温柔乡,唉~ 记得最离谱的是,我初学vk时,知乎上有人把renderPass机制批倒批臭,说这东西繁琐的要命,哎呀你看vk1.3有个dynamic rendering的拓展可以让我们摆脱这东西,快来用快来用!一时间好多vk学习文章都显摆上了,你看我也是能蔑视vk设计的人了,我也用上1.3拓展了。 他们没人提到这个拓展支持率目前百分之十出头,移动端更是全军覆没;而renderPass背后的深层逻辑我更是很少看到人阐述,好吧,幸好我看的vk文章没这么操蛋。 > 纠正一下,dynamic rendering是个1.2的拓展并在1.3成为核心,且在1.4会取代现有的renderpass机制,配合另一个1.3的拓展 VK_KHR_dynamic_rendering_local_read 就可以达到subpass的效果。 > 但 VK_KHR_dynamic_rendering_local_read 只有在1.4才被promoted到core,所以... > 我仍然觉得1.4之前的版本用dynamic rendering是个极大的错误。 所以别看知乎了,快来看窝这个三流引擎程序的博客 这里记录了我在游戏引擎这条路上的所有思考哦 ⓛ ω ⓛ <audio controls> <source src="https://pic.feiqi3.cn/media/_Dirty_Paws.mp3" type="audio/mpeg"> 这里原本应该是一首叫 dirty paws的歌,我也是dirty paws啦~ </audio>